紧接着决策树(一) 我们来介绍 CART,随机森林, Boosting 等一系列实用非常广泛的树模型.
5 CART
CART(Classification and regression tree)是由L.Breiman,J.Friedman,R.Olshen和C.Stone于1984年提出,是应用很广泛的决策树学习方法.
5.1 分类树
前面我们知道了ID3用信息增益来选择Feature,C4.5用信息增益比率来选择Feature,CART分类树用的是另外一个指标 – 基尼指数. 假设一共有个类,样本属于第类的概率是,则概率分布的基尼指数定义为:
对于二类分类问题,若样本属于正类的概率为 ,则基尼指数为:
对于给定的样本集合,其基尼指数定义为:
其中是中属于第类的样本子集.
如果样本集合被某个特征是否取某个值分成两个样本集合和,则在特征的条件下,集合的基尼指数定义为:
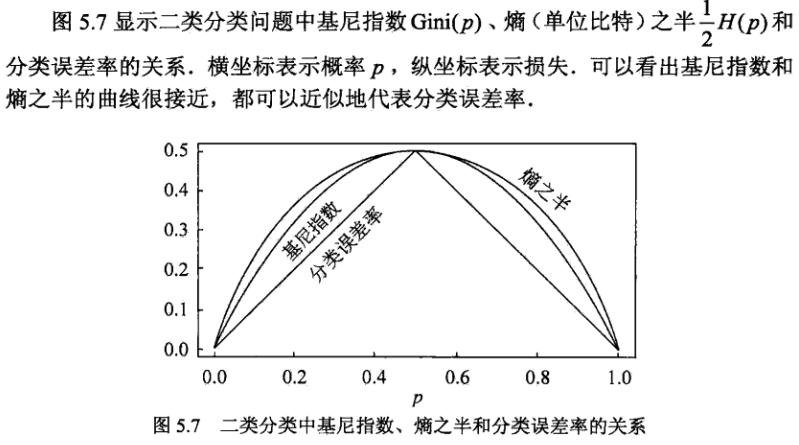
是不是跟条件熵的形式一致? 基尼指数反应的是集合的不确定程度,跟熵的含义相似.反应的是经过特征划分后集合的不确定程度.所以决策树分裂选取Feature的时候,要选择使基尼指数最小的Feature.再看看下图,其实基尼指数,熵,误分类率的曲线非常接近.
最后,请仿照ID3类似的计算步骤,生成文章开头关于贷款例子的决策树模型.
5.2 回归树
假设和分别为输入和输出变量,为连续变量,训练数据集为:
一个回归树对应着输入空间的一个划分以及在划分的单元上的输出值.加入已经将输入空间划分为个单元,在每个单元上有个固定的输出,则回归树表示为:
问题是怎么对输入空间进行划分.一般采用启发式的思路,选择第 个Feature 和他的取值分别作为切分变量和切分点,并定义两个区域:
然后采用平方误差损失求解最优的切分变量和切分点.
别看上面的式子很复杂,实际上不难理解,每一个切分变量和切分点对都将输入空间分成两个区域,然后分别求每个区域的输出值,使得误差最小,很显然输出值应该是那个区域所有样本值的平均值,即:
然后每个对里找出使总误差最小的对作为最终的切分变量和切分点,对切分后的子区域重复这一步骤.
看个例子,下面有一个简单的训练数据,根据这个数据集我们生成一棵回归树.
| x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| y | 5.56 | 5.70 | 5.91 | 6.40 | 6.80 | 7.05 | 8.90 | 8.70 | 9.00 | 4 |
由于只有一个Feature,我们不用选择,下面我们考虑如下的切分点: 1.5,2.5,3.5,4.5,5.5,6.5,7.5,8.5,9.5,然后求出对应的,以及总的误差:
得到结果:
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
| m(s) | 15.72 | 12.07 | 8.36 | 4.78 | 3.91 | 1.93 | 8.01 | 11.73 | 15.74 |
很显然应该取作为切分点,此时:
决策树为:
然后对区域重复这一过程构建完整的回归树.
6 剪枝
决策树剪枝分前剪枝(预剪枝)和后剪枝两种形式.
6.1 前剪枝
通过提前停止树的构造进行剪枝.
- 树到达一定高度
- 节点下包含的样本点小于一定数目
- 信息增益小于一定的阈值等等
- 节点下所有样本都属于同一个类别
6.2 后剪枝
后剪枝首先通过完全分裂构造完整的决策树,允许过拟合,然后采取一定的策略来进行剪枝,常用的后剪枝策略包括:
- 降低错误剪枝 REP(Reduced Error Pruning)
- 悲观错误剪枝 PEP(Pessimistic Error Pruning)
- 基于错误剪枝 EBP(Error Based Pruning)
- 代价-复杂度剪枝 CCP(Cost Complexity Pruning)
- 最小错误剪枝 MEP(Minimum Error Pruning)
- 等等
这里拿 CCP 举例,CART用的就是CCP剪枝,其余的剪枝方法可以网上google一下. CCP剪枝类实际上就是我们之前讲到的最小化结构风险,对决策树,结构风险定义为:
其中: 为模型对训练数据的误差.对分类树,可以采用熵,基尼指数等等.对回归树,可以采用平方误差, 为树的叶子节点个数, 为两者的平衡系数.
//TODO
7 优缺点
优点:
- 模型特别容易解释,甚至比线性模型有更好的解释性.
- 决策过程跟人的思维习惯特别接近.
- 能很清楚的图形化显示模型.
- 能很方便的处理一些定性的Feature.
缺点:
- 一般来说,准确率不如其他的模型.但有很多解方案,下面会逐一介绍.
- 不支持在线学习,有新样本来的时候,需要重建决策树.
- 很容易产生过拟合.
8 Bagging
决策树模型最大的一个问题就是非常容易过拟合,过拟合就是模型不稳定,High Variance,Bagging(或者说Boostrap aggreation)就是一种统计学习里常用的减少过拟合的方法.学习概率论的时候,我们知道个独立同分布(方差为)的随机变量,平均值记为,则的方差为.也就是说对很多个随机变量取平均值可以降低方差.Bagging就是基于类似的思想,用 个独立的训练集,训练出 棵决策树,然后把这些树加起来求平均.
对回归树来说,直接加起来求平均即可.对分类树来说,采用的是少数服从多数,求投票的策略.但实际上我们很难获得 个独立的训练数据集,怎么办? 还好我们有强大的 Boostrap 进行放回抽样,这样就能获得 个训练集了.Bagging里的每棵树都是High Variance,Low bias,平均起来之后成功的避免了High variance.
9 Random Forest
随机森林是对Bagging的一种改进,也是把许多棵树组合在一起,对新数据的预测方法和Bagging一样.在Bagging中,我们基于Boostrap的抽样训练了棵决策树,在每棵决策树里,树的每一次分裂都考虑了所有的Feature.但在随机森林里,树的分裂不是考虑所有的Feature,而是只考虑部分Feature.在建立每一棵决策树的过程中,有两点需要注意:采样与完全分裂.首先是两个随机采样的过,random forest对输入的数据要进行行,列的采样.对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本.假设输入样本为个,那么采样的样本也为个.这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting.然后进行列采样,从个feature中,选择个(m « M).之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类.一般很多的决策树算法都一个重要的剪枝步骤,但是这里跟Bagging一样,不需要这个步骤,由于之前的两个随机采样的过程保证了随机性,所以就算不剪枝,也不会出现over-fitting.按这种算法得到的随机森林中的每一棵都是很弱的,但是大家组合起来就很厉害了.可以这样比喻随机森林算法:每一棵决策树就是一个精通于某一个窄领域的专家(因为我们从M个feature中选择m让每一棵决策树进行学习),这样在随机森林中就有了很多个精通不同领域的专家,对一个新的问题(新的输入数据),可以用不同的角度去看待它,最终由各个专家投票得到结果.今天微软的Kinect里面就采用了Random Forest,相关论文Real-time Human Pose Recognition in Parts from Single Depth Images是CVPR2011的best paper.
Random Forest Vs Bagging:
- Rand forest是选与输入样本的数目相同多的次数(可能一个样本会被选取多次,同时也会造成一些样本不会被选取到),而bagging一般选取比输入样本的数目少的样本
- Bagging是用全部特征来得到分类器,而rand forest是需要从全部特征中选取其中的一部分来训练得到分类器
- 一般Rand forest效果比bagging效果好
10 Boosting
我们从一个例子来看看Boosting的思想,下面是一个房东和中介之间的对话.
- 房东:我有个100平的房子要卖,多少钱合适?
- 中介:大概3万一平,300万吧.在哪?
- 房东:在北四环里.
- 中介:那得加50万,350万.朝向如何?
- 房东:东南朝向的.
- 中介:不是南北朝向啊? 那得减20万,330万吧.哪年的房子?
- 房东:2009年的,挺新的.
- 中介:嗯,是挺新的,那得再加30万,360万吧…..
- 房东:……
上面房东和中介之间的对话过程就是一个典型的Boosting过程,每一次的对话都构成了一棵决策树,最终的结果把所有的决策树加起来就行了.
10.1 分类树
在后面讲Adaboost的时候再讲.
10.2 回归树
提升树公式化的表示为:
其中: 表示决策树,为决策树的参数,为树的个数.
提升树采用的是加法模型和前向分步算法(在Adaboost的时候会详细讲到),第步的模型为:
每轮都通过极小化经验风险来确定决策树的参数:
回归树仍然采用的是平方损失函数:
所以:
这里 为当前模型拟合数据的残差(Residual),所以对回归问题的提升树算法来说,只需要简单拟合当前模型的残差.
回归问题的提升树算法:
- 初始化
- 对
- 计算残差
- 根据残差拟合一个回归树
- 更新
- 得到回归问题提升树模型
以CART中回归树的例子来看看Boosting怎么做. 第一次切分之后我们已经得到了回归树模型:
计算用拟合数据之后得到测残差:
| x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| r | -0.68 | -0.54 | -0.33 | 0.16 | 0.56 | 0.81 | -0.01 | -0.21 | 0.09 | 0.14 |
用同样的步骤,对上面的残差拟合出一棵决策树:
如此下去,直到最后总的误差小于一定的阈值.
Bagging与Boosting的区别:
- Bagging的训练集的选择是随机的,各轮训练集之间相互独立,而Boostlng的各轮训练集的选择与前面各轮的学习结果有关.
- Bagging的各个预测函数可以并行生成,而Boosting的各个预测函数只能顺序生成.对于象神经网络这样极为耗时的学习方法,Bagging可通过并行训练节省大量时间开销.
- Bagging和boosting都可以有效地提高分类的准确性,在大多数数据集中,boosting的准确性比bagging高.
对于Adaboost:
- Bagging采用均匀取样,而Boosting根据错误率来取样,因此Boosting的分类精度要优于Bagging.
- Bagging的各个预测函数没有权重,而Boosting是有权重的.
11. 实例演示
下面通过几个例子来看看各种树之间的区别.
11.1 分类树
Carsearts数据集是400个不同店铺关于儿童汽车座椅的模拟销售数据,包括销量Sales,竞争对手的售价ComPrice,当地平均收入Income,广告预算Advertising,人口Population,售价Price,座椅排架的位置ShelveLoc,当地人口的平均年龄Age,教育水平Education,店铺在市区还是农村Urban,是否在美国US.
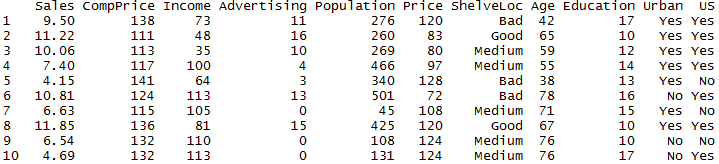
将销量超过8(单位:千)定义为销量高,小于8定义为销量低,以销量作为类别生成一棵决策树,代码如下:
library(tree)
library(ISLR)
attach(Carseats)
High=ifelse(Sales<=8, "No", "Yes")
Carseats=data.frame(Carseats, High)
tree.carseats=tree(High~.-Sales, Carseats)
summary(tree.carseats)
plot(tree.carseats)
text(tree.carseats, pretty=0)
tree.carseats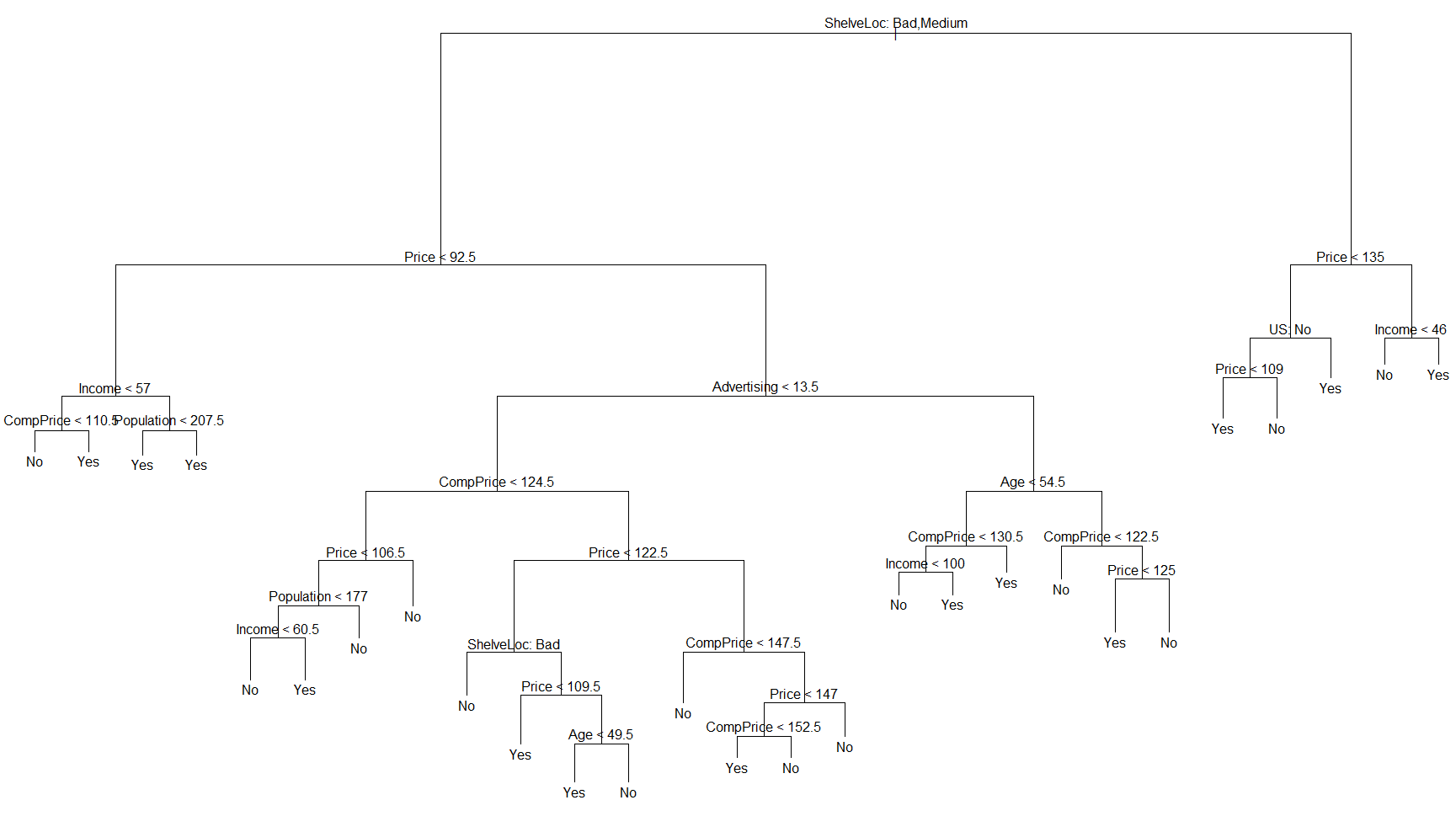
生成的树一共有27个叶子节点,36个点分错,错误率为 36/400 = 0.09,平均残差(Residual mean deviance)为0.4575,对分类树,平均残差的计算方式为:
表示第个节点中,有多少个属于类别
的大小表示子节点个数.
从生成的树可以看出,最重要的Feature是 ShelveLoc,构成了树的第一个节点.
set.seed(2)
train=sample(1:nrow(Carseats),200)
Carseats.test=Carseats[-train,]
High.test=High[-train]
tree.carseats=tree(High~.-Sales, Carseats, subset=train)
tree.pred=predict(tree.carseats, Carseats.test, type="class")
table(tree.pred, High.test)| tree.pred\High.test | No | Yes |
| No | 86 | 27 |
| Yes | 30 | 57 |
准确率为 (86+57)/200 = 0.715
用误分类率来剪枝,做交叉验证,代码如下:
set.seed(3)
cv.carseats=cv.tree(tree.carseats, FUN=prune.misclass)
names(cv.carseats)
cv.carseats
par(mfrow=c(1, 2))
plot(cv.carseats$$size, cv.carseats$$dev, type="b")
plot(cv.carseats$$k, cv.carseats$$dev, type="b")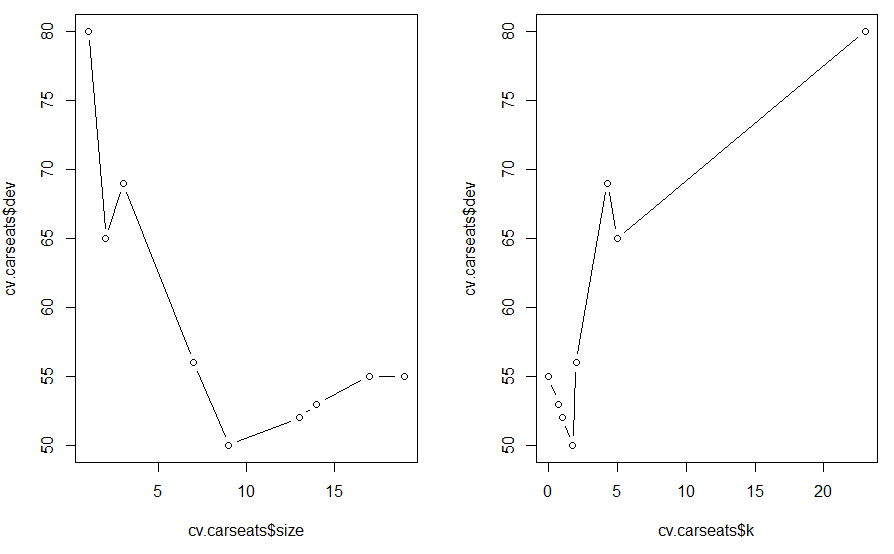
随着树的节点越来越多(树越来越复杂),deviance逐渐减小,然后又开始增大. 随着对模型复杂程度的惩罚越来越重(k越来越大),deviance逐渐减小,然后又开始增大.
思考 是不是跟我们在模型选择与调试里讲的结论一致?
从左边的图可以看出,当树的节点个数为 9 时,deviance达到最小.
我们分别画出9个叶子节点的树和15个叶子节点的树:
prune.carseats=prune.misclass(tree.carseats, best=9)
plot(prune.carseats)
text(prune.carseats, pretty=0)
tree.pred=predict(prune.carseats, Carseats.test, type="class")
table(tree.pred, High.test)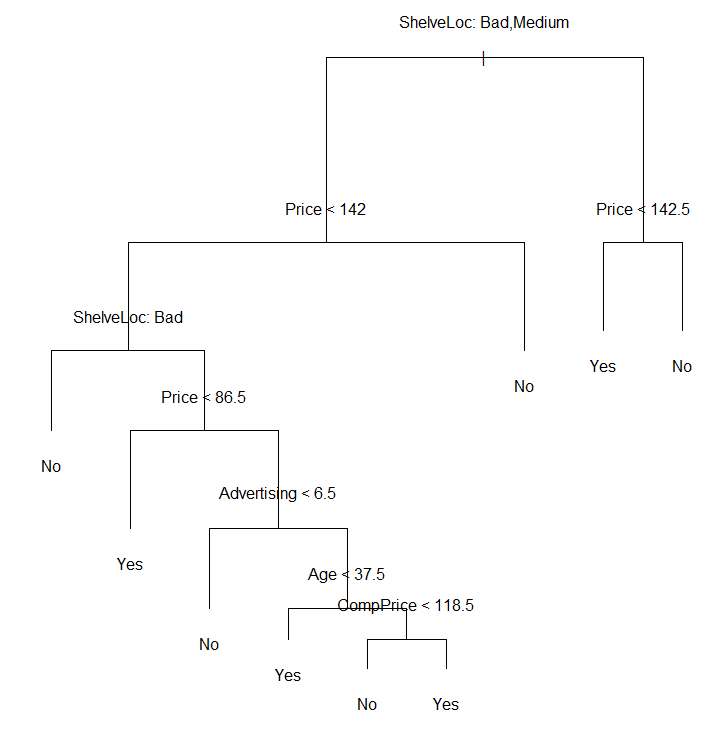
| tree.pred\High.test | No | Yes |
| No | 94 | 24 |
| Yes | 22 | 60 |
准确率为 (94+60)/200=0.77
prune.carseats=prune.misclass(tree.carseats, best=15)
plot(prune.carseats)
text(prune.carseats, pretty=0)
tree.pred=predict(prune.carseats, Carseats.test, type="class")
table(tree.pred, High.test)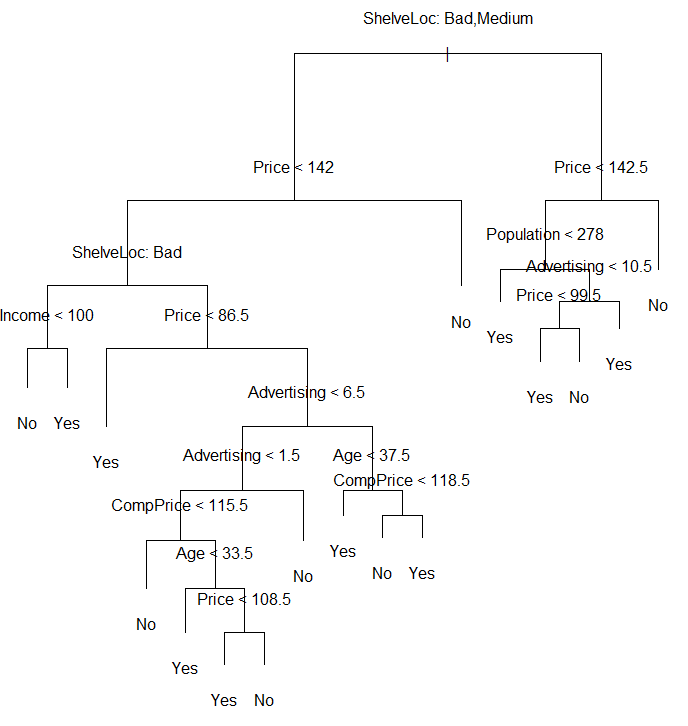
| tree.pred\High.test | No | Yes |
| No | 86 | 22 |
| Yes | 30 | 62 |
准确率为 (86+62)/200=0.74
11.2 回归树
Boston 数据集包括了506条Boston的房价数据,每条数据包括13个Feature.
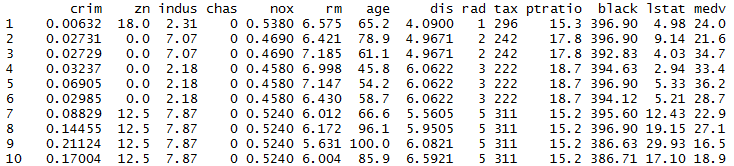
library(MASS)
set.seed(1)
train = sample(1:nrow(Boston), nrow(Boston)/2)
tree.boston=tree(medv~., Boston, subset=train)
summary(tree.boston)
plot(tree.boston)
text(tree.boston, pretty=0)
yhat=predict(tree.boston, newdata=Boston[-train,])
boston.test=Boston[-train, "medv"]
plot(yhat, boston.test)
abline(0, 1)
mean((yhat-boston.test)^2)
#[1] 25.04559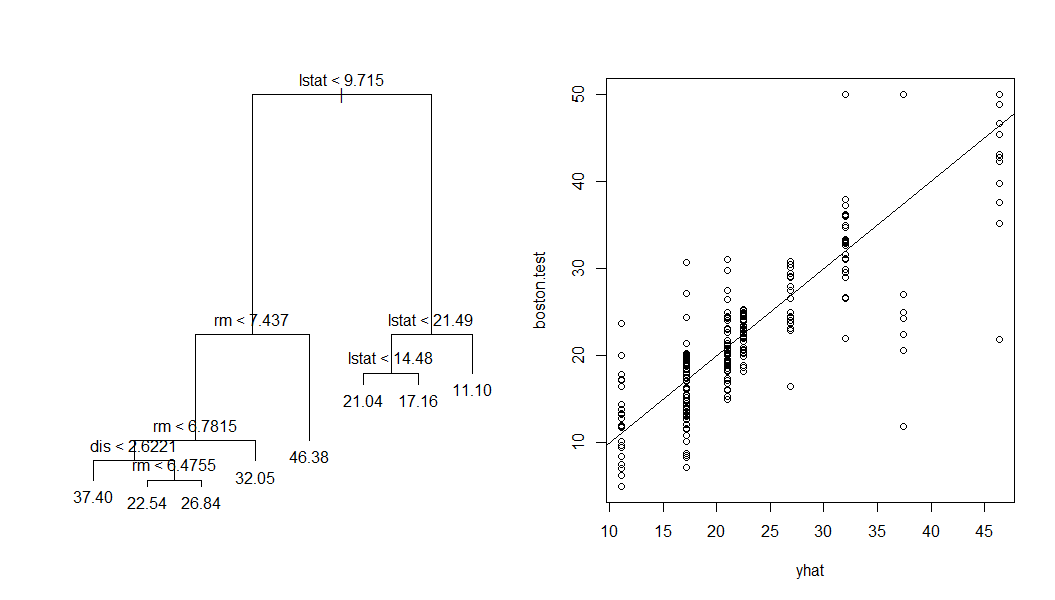
生成的树一共 8 个叶子节点,平均平方误差(Mean Squared Error,MSE) 为 25.05.
同样,做一下交叉验证:
cv.boston=cv.tree(tree.boston)
plot(cv.boston$$size, cv.boston$$dev, type='b')
prune.boston=prune.tree(tree.boston, best=5)
plot(prune.boston)
text(prune.boston, pretty=0)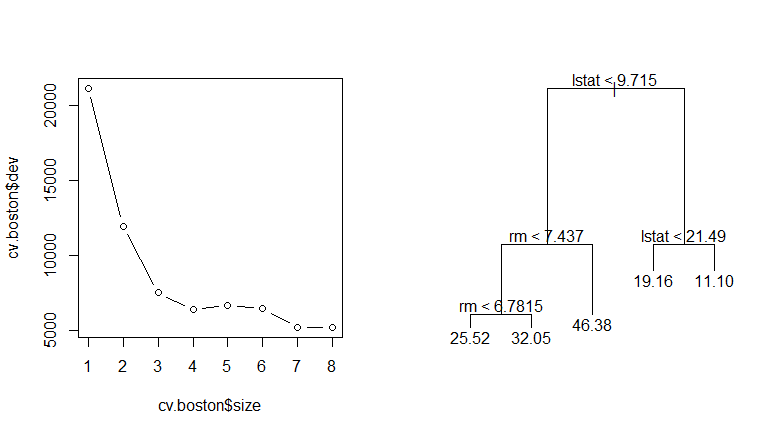
从左边的图可以看出,交叉验证最好的选择就是节点数为 8 的树,右边的图是强制剪枝为 5 个节点之后的结果.
11.3 Bagging和Random forest
下面看看 Bagging 和 Random forest 的试验结果.
Bagging和Random forest的区别在于Bagging是所有的Feature都参与Spliter的选择,而Random forest只有部分Feature参与Spliter的选择,R的randomForest包默认为回归树选择1/3的Feature,为分类树选择所有Feature数的平方根个Feature,将Bagging参与选择的Feature设为整个数据集的Feature数13.
library(randomForest)
set.seed(1)
bag.boston=randomForest(medv~.,data=Boston, subset=train, mtry=13, importance=TRUE)
bag.boston
yhat.bag = predict(bag.boston, newdata=Boston[-train,])
plot(yhat.bag, boston.test)
abline(0, 1)
mean((yhat.bag-boston.test)^2)
#[1] 13.47349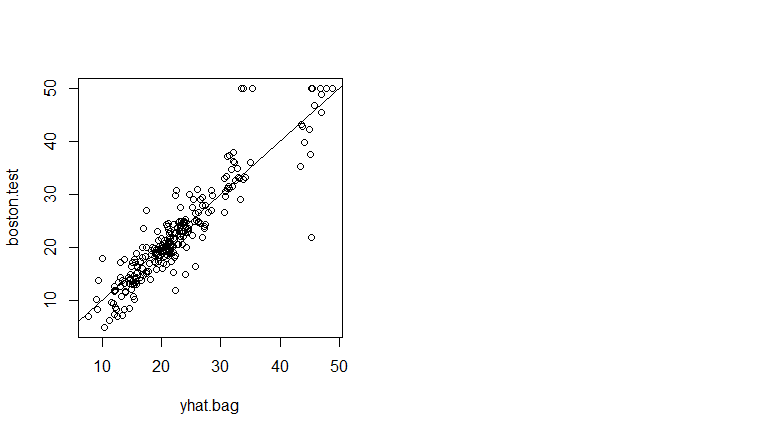
Bagging的MSE为13.5,大概只有原来误差(25.05)的一半.
将Random forest参与选择的Feature设为6.
set.seed(1)
rf.boston=randomForest(medv~.,data=Boston,subset=train,mtry=6,importance=TRUE)
yhat.rf = predict(rf.boston,newdata=Boston[-train,])
mean((yhat.rf-boston.test)^2)
#[1] 11.48022Random forest的MSE约为11.5,比Bagging的误差还要小.
11.4 Boosting
//TODO
12 参考资料
- 统计学习方法 李航著
- 机器学习 Tom M.Mitchell 著
- http://blog.csdn.net/v_july_v/article/details/7577684
- http://www-bcf.usc.edu/~gareth/ISL/
- http://www-bcf.usc.edu/~gareth/ISL/Chapter%208%20Lab.txt
- http://blog.csdn.net/xianlingmao/article/details/7712217