我们为什么要千辛万苦训练一个模型呢? 目的是为了拿这个训练好的模型对以后可能遇到的未知数据来做一些预测, 判断, 分类等等. 既然是这个目的, 那很自然的我们应该用模型在未知数据上的表现来衡量一个模型的好坏. 我们管模型在未知数据上的预测能力叫模型的泛化能力(generalization ability). 对未知数据的误差叫泛化误差(generalization error), 泛化误差的大小就反应了一个模型的好坏. 但实际上我们根本收集不到这些”未知数据”, 所以我们经常将训练数据一分为二, 用其中的一部分当真正的训练数据, 用另外一部分当”未知数据”, 也就是测试数据, 这时候评价一个模型的过程为:
- 在训练集上通过最小化损失函数 学习得到模型参数 .
- 在测试集上计算模型的误差:
我们再来看看用这种方式怎么解决欠拟合与过拟合里提到的曲线拟合. 我们的目标是要找到合适的多项式次数 , 这个过程为:
- 对每一个可能的多项式次数, 在训练集上通过最小化损失函数 学习得到模型参数 .
- 对每一个学到的模型参数 , 计算在测试集上的误差.
- 选择使测试集上误差最小的那个多项式次数 .
但是这种做法有一个问题, 就是测试数据集直接参与了我们选择模型, 如果我们换一个测试数据集, 这个模型的误差没准就会变大很多, 怎么解决这个问题呢?
其实训练数据就好比我们平时的测验题, 测试数据就好比我们的高考试题. 没有高考之前, 我们倾向于认为平时测验成绩比较高的高考成绩也会比较好. 但最终还是要由高考成绩来得出结果(高考制度不一定科学, 我只是拿来举例). 想想我们平时是不是还有大型的模拟考试? 我们也可以考虑引入这样一个数据集, 于是我们把我们收集到的数据分为三个集合, 一个是真正的训练集, 还有一个叫交叉验证(cross validation)集, 最后一个就是测试集.
有了训练集, 交叉验证集和测试集之后, 我们的多项式次数选择过程变为:
- 对每一个可能的多项式次数, 在训练集上通过最小化损失函数 学习得到模型参数 .
- 对每一个学到的模型参数 , 计算在交叉验证集上的误差.
- 选择使交叉验证集误差最小的那个多项式次数 .
- 用步骤3对应的 计算在测试集上的误差作为模型最终的泛化误差.
注意: 在测试集上的误差并不是模型真正的泛化误差, 只是我们一般用来替代泛化误差. 测试数据集唯一的作用就是用来输出模型的泛化误差.
在欠拟合与过拟合的文章中说到, 我们的模型是要在 bias 和 variance 之间找到一个平衡, 当我们调试模型的时候, 怎么知道我们的模型的问题到底是 high bias 还是 high variance 呢? 我们可以根据在训练集和交叉验证集上的误差来判断.
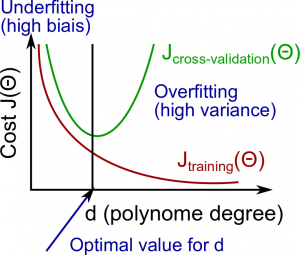
从上图可以看出, 随着模型越来越复杂(越来越大), 训练误差会越来越小, 验证集上的误差会先降低然后升高.
High bias(欠拟合)时
- 和 都比较大, 并且
High variance(过拟合)时
- 比较小, 并且
再来看看正规化项(由大小决定)和训练误差, 交叉验证集的误差之间的关系.
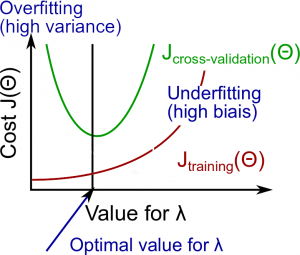
从上图可以看出, 随着对模型复杂度的惩罚越来越重(越来越大), 训练误差会越来越大, 验证集上的误差会先降低然后升高.
较小时, high variance, 过拟合
- 较小, 较大
适中时
- 和 都较小, 并且
较大时, high bias, 欠拟合
- 和 都较大
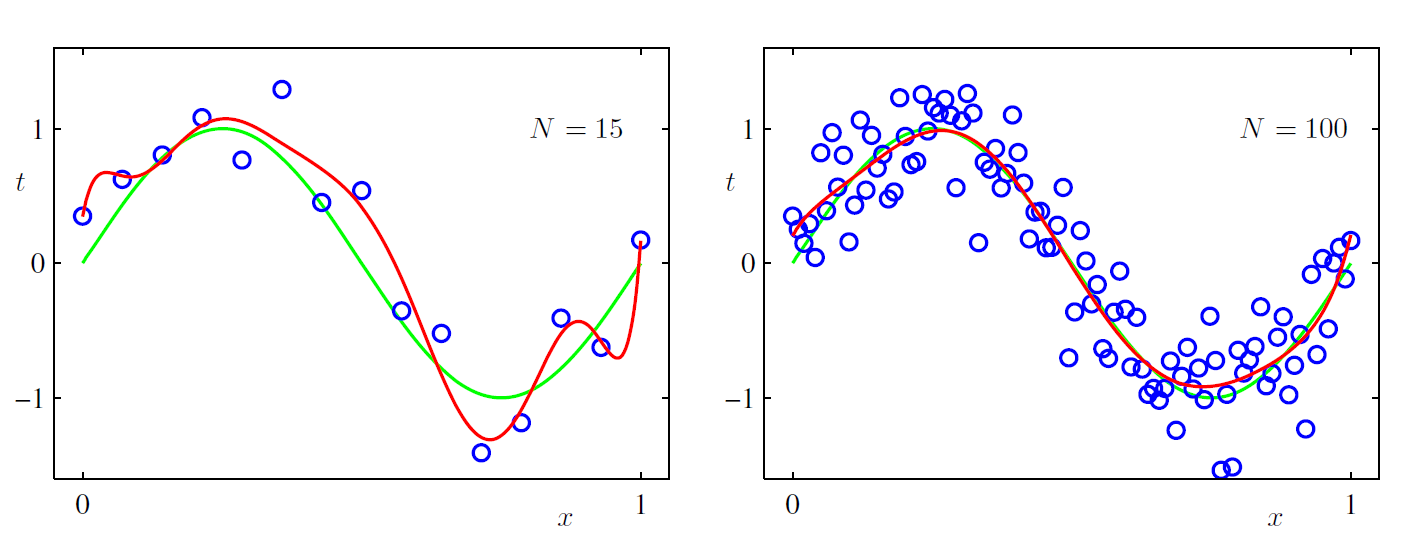
其实训练集的大小对模型的误差也会有影响, 只是实际工程中我们获取更多的训练集往往比较困难, 回头再看看在欠拟合与过拟合的文章中提到的曲线拟合的例子, 如果我们非要用9次方曲线去拟合, 而且不想加入正规化项, 增加训练集的大小就可以了, 如下图所示:
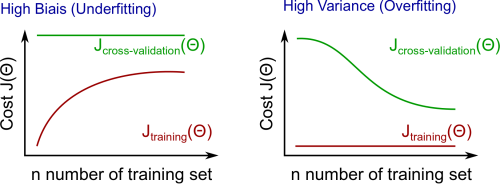
训练数据集大小和训练误差, 交叉验证集的误差之间的关系如下:
在调试过程中, 我们既要选出合适的模型, 又要选择合适的正规化项系数 , 我们来看看这个选择过程:
- 设定一系列的 值, 比如
- 选择一个 计算
- 设定模型集合, 比如一次多项式, 二次多项式, … , 逻辑回归, SVM 等等.
- 选定一个模型, 并用选好的 在训练集上学习出模型参数
- 用学好的参数 计算在交叉验证集上的误差
- 对每一个模型, 组合都计算出相应的交叉验证集误差
- 选择交叉验证集误差最小的模型和组合
注意: 一旦学习出参数, 然后用这个参数计算交叉验证集误差的时候不需要计算正规化项了.
最后, 再总结一下:
修正欠拟合 high bias
- 减小正规化项的系数
- 增加模型复杂度, 比如升高多项式次数
- 增加Feature(实际上也是增加模型复杂度?)
修正过拟合 high variance
- 增加正规化项的系数
- 减少Feature
- 增加训练集
我们前面提到的交叉验证实际上是简单的交叉验证, 实际工程中用得更多的是 k-folder cross validation, 详细信息请参考这里.
训练数据是多多益善, 越多越好, 数据多了, 即使很简单的算法也能得出让人满意的结果. Feature一定要包含最够多的信息, 如果一个专家能通过这些Feature很自信地得出预测结果, 那Feature的信息就够了.